معرفی و آموزش نرمافزار ScientoPy
چند وقت پیش با نرمافزار ScientoPy از طریق مقالهای که طراحانش در مجله ساینتومتریک منتشر کرده بودند آشنا شدم. این نرمافزار قابلیتهای زیادی در مصورسازی مجموعه مقالات داره و از این رو میتونه برای کسایی که قصد بررسی مجموعهای از مقالات رو دارند، مثلا افرادی که میخوان در هنگام نگارش مرور نظاممند، یک مرور اجمالی از مجموعهشون داشته باشند میتونه مفید باشه. کار با این نرمافزار بسیار ساده هست و در دو نسخه بدون رابط کاربری و با رابط کاربری عرضه شده. در ادامه مطلب به آموزش این نرمافزار میپردازیم.
آموزش نرمافزار ScientoPy
آموزش نصب
همونطور که از اسم این نرمافزار میشه فهمید، ساینتوپای به زبان پایتون نوشته شده و برای اجرای اون باید ابتدا پایتون رو روی سیستمتون نصب کنید.
1- برای نصب پایتون، به سایت پایتون مراجعه کنید و جدیدترین نسخه از پایتون ورژن 3 رو دانلود کنید.
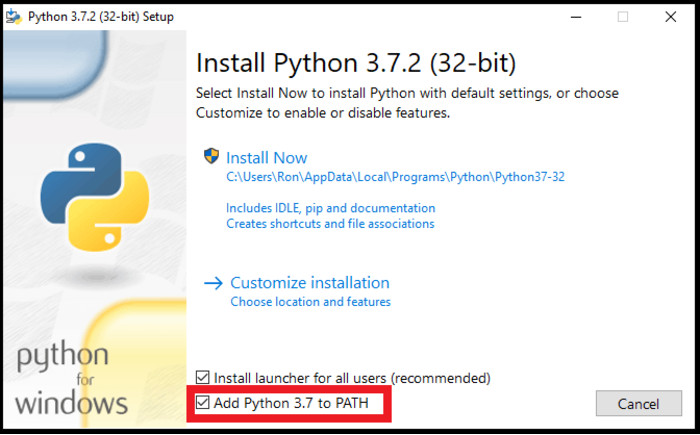
2- در هنگام نصب پایتون توجه داشته باشید که تیک “Add Python 3.7 to PATH” رو مطابق تصویر زیر فعال کنید.
3- اگر میخواید که ساینتوپای براتون ابر واژگانی از مجموعه مقالات رو بسازه، نیاز هست که Microsoft Visual C++ Redistributable for Visual Studio 2017 رو هم نصب کنید. برای نصب این مجموعه اینجا کلیک کنید (حجمش زیاده، حدود 4 گیگابایت. اگه ترسیم ابر واژگانی زیاد براتون مهم نیست از خیرش بگذرید).
4- حالا باید کتابخونههایی که ساینتوپای ازشون استفاده میکنه رو روی پایتون نصب کنید. برای اینکار در ویندوز دکمه win+r رو فشار بدید تا صفحه Run باز بشه و بعد توی اون cmd رو تایپ و اینتر بزنید.
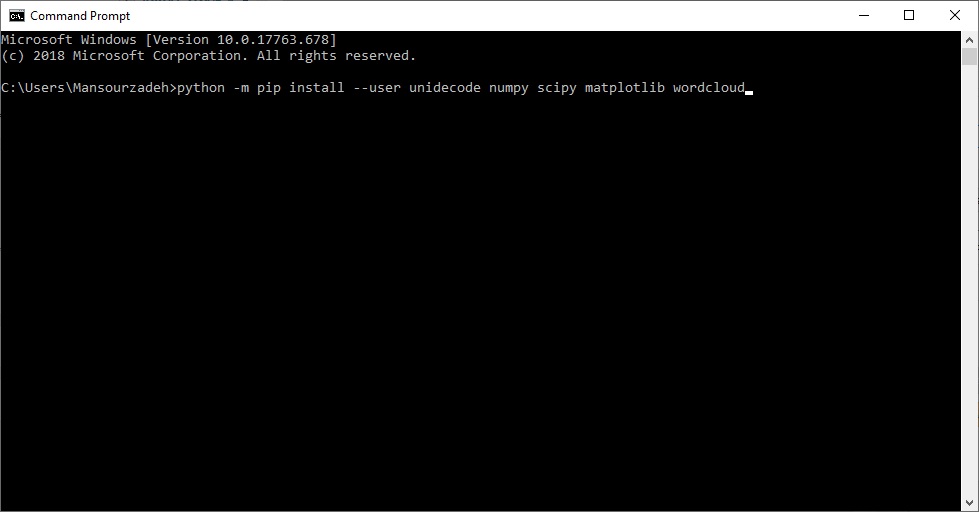
با این کار صفحه فرمان ویندوز براتون باز میشه، در این صفحه کد زیر رو تایپ کنید و اینتر بزنید تا کتابخونههای لازم نصب بشن.
python -m pip install --user unidecode numpy scipy matplotlib wordcloud
5- حالا آخرین نسخه از ساینتوپای رو از این لینک دانلود کنید.
کار با نرمافزار
1- دانلود دیتا
اول باید دیتای مورد نظرتون رو از طریق WoS و یا Scopus دانلود کنید. بدین منظور استراتژی جستجوی مورد نظرتون رو در این پایگاهها اجرا کنید.
برای خروجی گرفتن از پایگاه wos باید مطابق تصویر زیر در لیست نتایج جستجو روی دکمه Save in Other File Formats کلیک کنید.
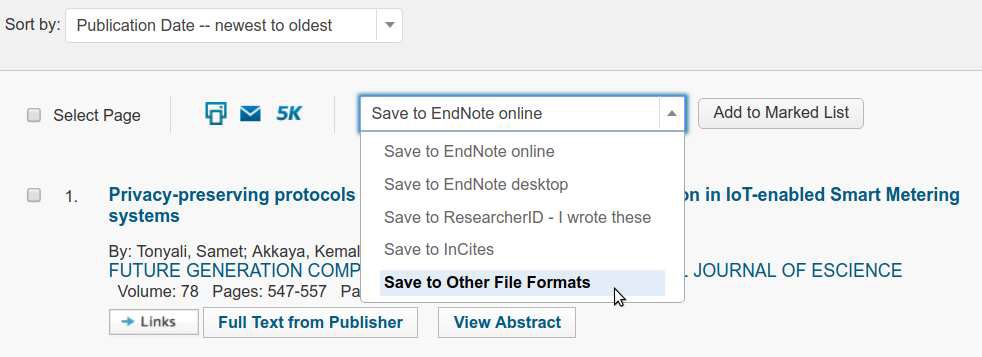
و در صفحه جدیدی که باز میشه تعداد رکوردهایی که میخواید دانلود کنید رو وارد کنید و نوع محتوای دانلودتون رو روی Full Record and Cited References و فرمت فایل رو روی Tab-delimited (Win, UTF-8) تنظیم کنید.
نکته: اگر لیست نتایج جستجوی شما بیشتر از 500 رکورد باشه، باید بصورت فایل های جداگانه 500 تایی دانلود کنید. یک بار از 1 تا 500، بار بعد از 501 تا 1000 و ...
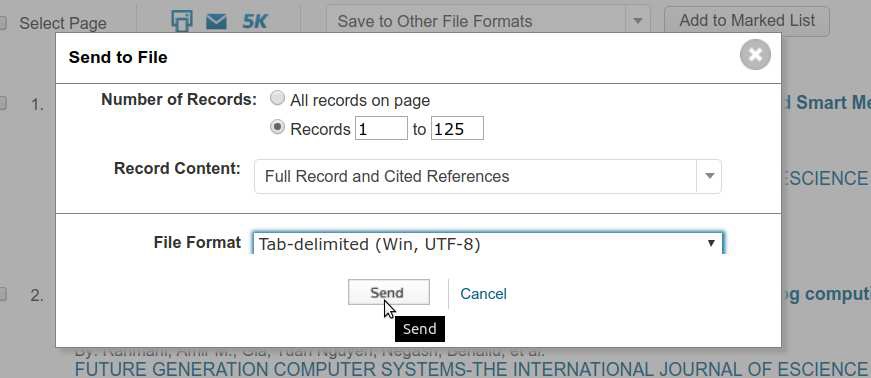
برای گرفتن خروجی از اسکوپوس هم در لیست نتایج روی Export کلیک کنید.
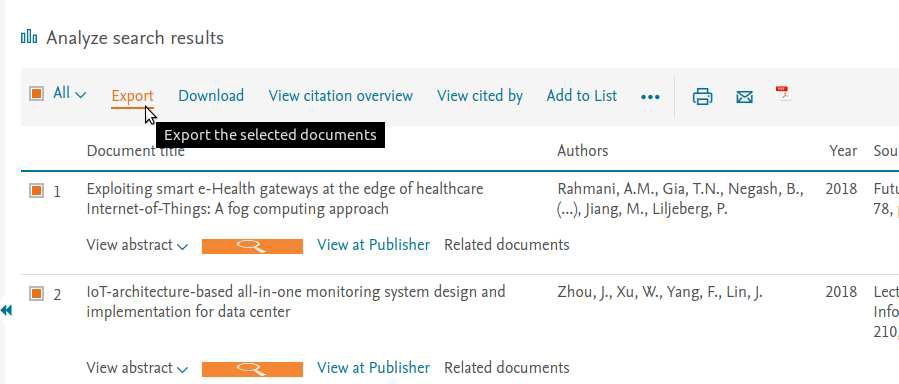
و بعدش فرمت CSV (Excel) رو انتخاب و مطابق تصویر زیر، داده های مورد نیاز رو انتخاب کنید.

حالا شما دو یا چند فایل از نتایج جستجوتون دارید که میتونید ازشون برای تحلیلهای بعدی استفاده کنید. این فایلها رو در یک فولدر قرار بدید و اون رو در فولدر نرمافزار ساینتوپای که دانلود کردید قرار بدید. من این فایلها رو در فولدر ScientoPy/dataIn/ قرار دادم
اجرای پیش پردازش
ما الان دو یا چند فایل داریم که از دو پایگاه اطلاعاتی مختلف گرفتیم. معلومه که نمیتونیم مستقیما باهاشون کار کنیم. برای اینکار ساینتوپای ابتدا یک سری فعالیتهای پیش پردازشی رو انجام میده که این فایلهای مختلف رو با هم ترکیب، و موارد تکراری رو حذف کنه.
برای این کار ابتدا خط فرمان رو اجرا کنید و با کد زیر، وارد فولدر ساینتوپای بشید. من ساینتوپای رو توی دسکتاپم ریختم و از مسیر زیر استفاده میکنم. شما اگر در جای دیگهای ریختید باید مسیر فولدر ساینتوپای خودتون رو وارد کنید.
cd C:\Users\your_username\Desktop\ScientoPy
حالا باید پایتون رو فراخوانی کنید و دستور پیش پردازش داده هایی که در فولد dataIn هستند رو اجرا کنید:
python preProcess.py dataIn
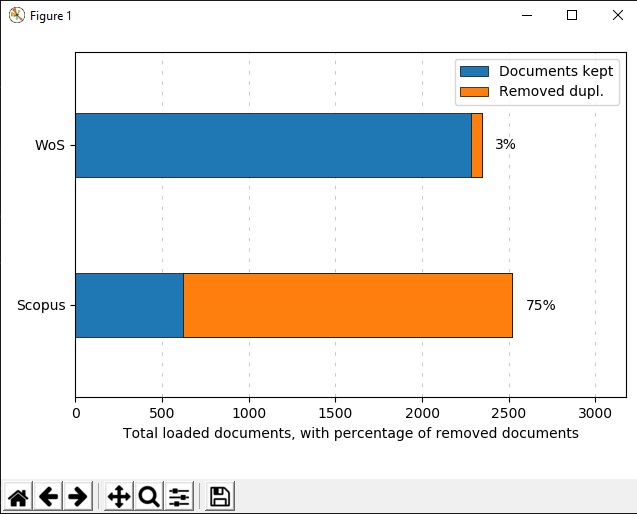
بعد از اجرای دستور فوق، یه نمودار برای شما نشان داده میشه که درش تعداد مدارک هر کدوم از پایگاه ها و میزان مدارک تکراری رو نشون میده:
استخراج اطلاعات
خب الان دادهها آماده اجرای تحلیلهای ما هستند. حالا با اجرای کد scientoPy.py -c و ترکیبش با تگهای زیر، میتونید برترینهای هر کدوم از تگها رو مشاهده کنید.
author ===>Authors last name and first name initial
sourceTitle ===>Publication or journal name
subject ===>Research areas, only from WoS documents
authorKeywords ===>Author keywords
indexKeywords ===>Keywords generated by the index, from WoS {Keyword Plus}, and from Scopus { Indexed keywords}
bothKeywords ===>AuthorKeywords and indexKeywords are used for this search
abstract ===>Document abstract, for use with pre-defined topics and asterisk wildcard
documentType ===>Type of document
dataBase ===>Database where the document was extracted (WoS or Scopus)
country ===>Country extracted from authors affiliations
institution ===>Institution extracted from authors affiliations
institutionWithCountry ===>Institution with country extracted from authors affiliations
به عنوان مثال، با اجرای کد زیر، میتونید 10 نویسنده برتر در مجموعهتون رو مشاهده کنید:
python scientoPy.py -c author
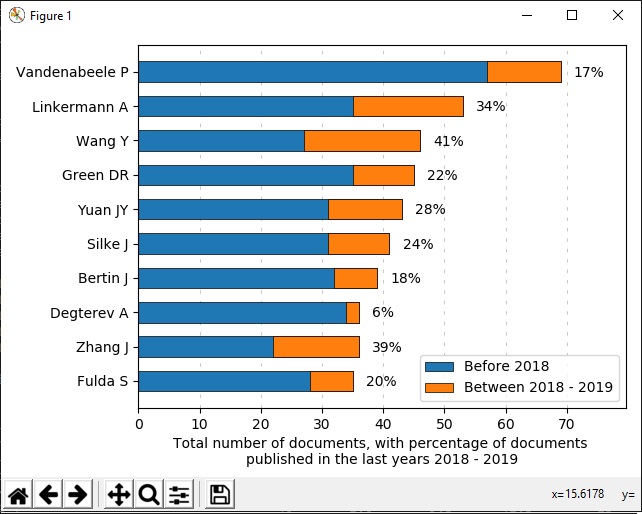
نکته: بصورت پیشفرض 10 مورد برتر از موارد فوق بشما نشان داده میشه. اگه به تعداد بیشتری نیاز دارید باید بوسیله دستور l- تعداد مورد نظرتون رو وارد کنید. مثال: 30 کشور برتر:
python scientoPy.py -c country -l 30
امکان مصورسازی دستورهای شما به وسیله انواع دیگر گرافها هم وجود داره. این گرافها عبارتند از:
Time line==> -g time_line
Horizontal bars==> -g bar
Evolution==> -g evolution
Word cloud==> -g word_cloud
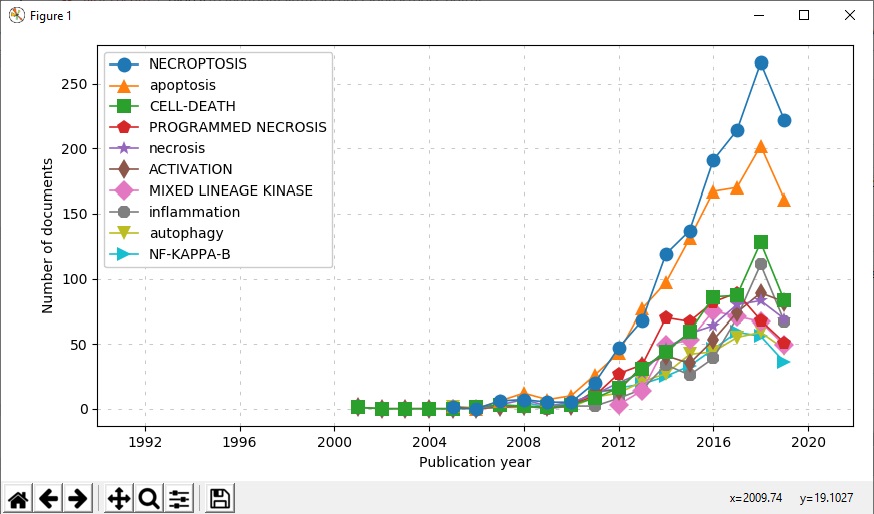
به عنوان مثال، کد زیر 10 کلیدواژه برتر رو در گذر زمان بهتون نشون میده:
python scientoPy.py -c authorKeywords -g time_line
این نرمافزار قابلیتهایی هم برای تحلیل موضوعات بهتون میده که میتونید با مشاهده این مقاله که نمونهای از این تحلیلهاست ازش برای کار خودتون ایده بگیرید.







سلام و عرض ادب،
بنده برای اجرای ScienoPy تمام مراحل شما را اجراء می کنم اما مسیر فولدر ScientoPy را نمی تواند بشناسد.
لطفاً راهنمایی بفرمایید.
تشکر